Giới thiệu
Tổng quan
Data Lake là một thuật ngữ chuyên môn có liên quan đến Big Data (Dữ liệu lớn). Data Lake đơn giản là nơi chứa dữ liệu thô (chưa xử lý) chờ được xử lý phân tích và đưa ra các đánh giá nhận xét (insight).
Data Lake có các tính chất sau:
- Thu thập mọi thứ – chứa tất cả dữ liệu dạng thô hoặc đã được xử lý trong khoảng thời gian dài.
- Đa người dùng – cho phép nhiều người dùng tinh chỉnh, khám phá và làm phong phú dữ liệu.
- Truy cập linh hoạt – hỗ trợ nhiều cách thức truy cập dữ liệu (access pattern) trên cơ sở hạ tầng dùng chung: lô (batch), tương tác, trực tuyến, tìm kiếm, trong bộ nhớ và các công cụ xử lý khác.
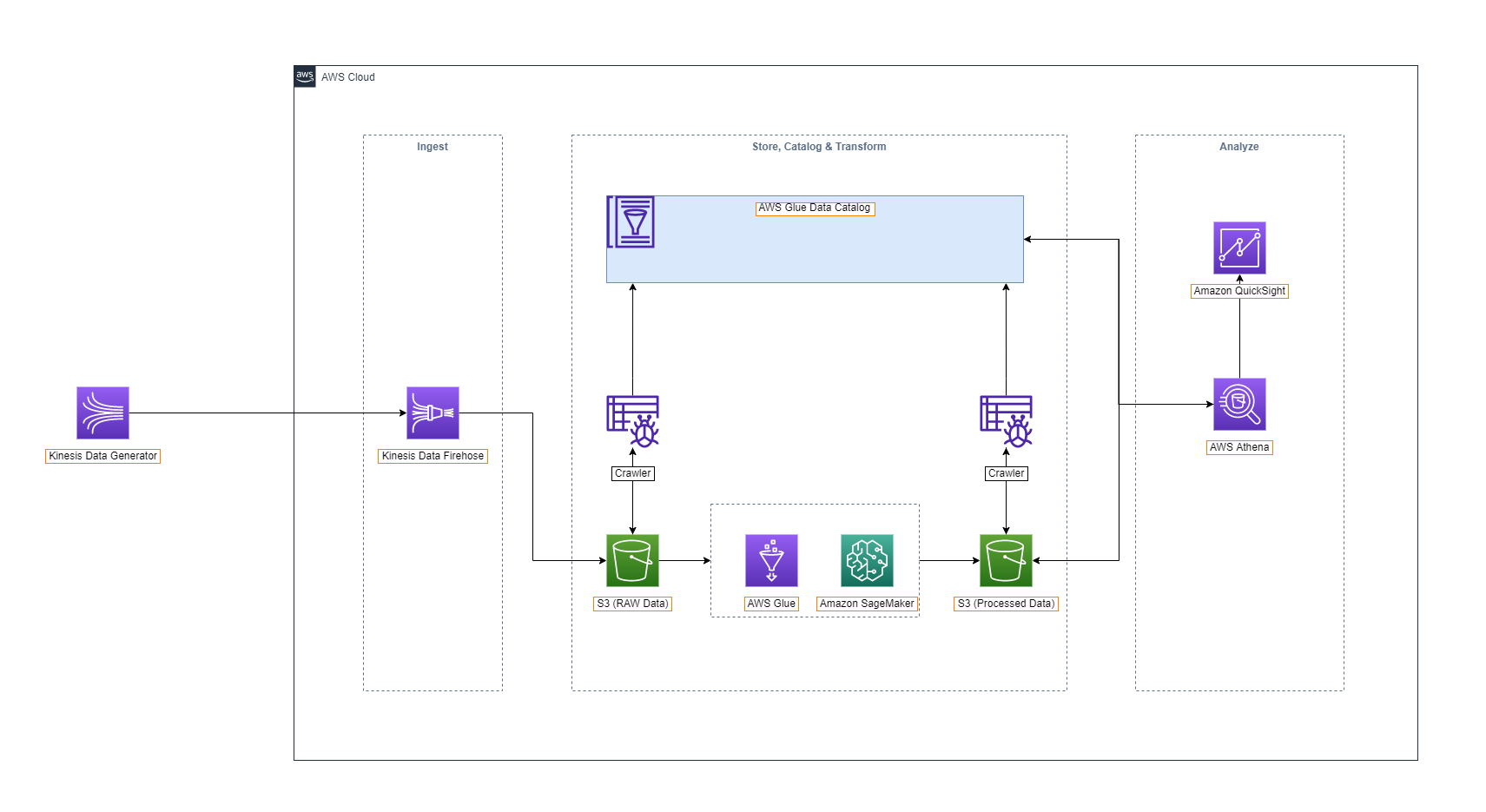
Amazon Glue: là một dịch vụ ETL hoàn chỉnh. Bạn có thể sử dụng Glue Crawler để nhận diện dữ liệu của bạn và lưu trữ thông tin dữ liệu (metadata) liên quan (ví dụ: định nghĩa bảng và schema) trong Glue Data Catalog. Sau khi được phân loại, dữ liệu của bạn có thể được tìm kiếm ngay, truy vấn và sẵn sàng cho các công việc ETL.
AWS Glue ETL có thể tạo mã để thực hiện công việc chuyển đổi dữ liệu và đưa dữ liệu vào vùng lưu trữ. AWS Glue có khả năng tạo mã Python có thể tùy chỉnh, tái sử dụng.
Sau khi các ETL Job của bạn đã sẵn sàng, chúng ta có thể tạo lịch để chạy trên môi trường Apache Spark có khả năng mở rộng lớn được quản lý bởi AWS Glue.

Amazon Athena: một dịch vụ truy vấn tương tác được sử dụng để phân tích dữ liệu trong Amazon S3 với SQL tiêu chuẩn. Chúng ta chỉ cần trỏ đến dữ liệu của bạn trong Amazon S3, xác định schema và bắt đầu truy vấn bằng trình chỉnh sửa truy vấn tích hợp. Amazon Athena cho phép chúng ta khai thác tất cả dữ liệu của mình trong Amazon S3 mà không cần phải thiết lập các quy trình ETL phức tạp. Amazon Athena tính tiền dựa trên các truy vấn được chạy.
Amazon Athena sử dụng Presto với hỗ trợ SQL ANSI và hoạt động với nhiều định dạng dữ liệu tiêu chuẩn, bao gồm CSV, JSON, ORC, Avro và Parquet. Athena được khuyến nghị cho nhu cầu truy vấn nhanh, nhưng nó cũng có thể xử lý các phân tích phức tạp, bao gồm các phép Join với lượng dữ liệu lớn, các window functions và mảng.

Amazon QuickSight: một dịch vụ biểu diễn dữ liệu được quản lý hoàn toàn bởi AWS.

-
Data source là một kho lưu trữ dữ liệu bên ngoài và bạn cần cấu hình việc truy cập dữ liệu trong kho dữ liệu bên ngoài này, ví dụ. Amazon S3, Amazon Athena, Salesforce, v.v.
-
Dataset xác định dữ liệu cụ thể trong Data source mà bạn muốn sử dụng. Ví dụ: Data source có thể là một bảng nếu bạn đang kết nối với Data source cơ sở dữ liệu. Nó có thể là một file nếu bạn đang kết nối với Data source Amazon S3.
-
Analysis là nơi chứa một tập hợp các Visual và câu chuyện có liên quan, ví dụ như tất cả các câu chuyện áp dụng cho một mục tiêu kinh doanh nhất định hoặc KPI.
-
Visual là một biểu diễn đồ họa cho dữ liệu của bạn. Bạn có thể tạo nhiều loại Visual khác nhau trong một analysis, sử dụng các bộ dữ liệu và loại Visual khác nhau.
-
Dashboard là một trang bao gồm một hoặc nhiều Analysis chỉ cho phép xem mà bạn có thể chia sẻ với những người dùng Amazon QuickSight khác cho mục đích báo cáo. Dashboard lưu giữ cấu hình của bản Analysis tại thời điểm bạn xuất bản nó, bao gồm những thứ như lọc, tham số, điều khiển và thứ tự sắp xếp.