Data Lake on AWS
Overview
Data Lake is a technical term related to Big Data. Simply put, a Data Lake is a repository for raw (unprocessed) data awaiting analysis to provide insights.
Data Lake possesses the following characteristics:
- Collects everything – it contains all types of data, whether raw or processed, over a long duration.
- Multi-user – it allows multiple users to refine, explore, and enrich the data.
- Flexible access – it supports various data access methods on a shared infrastructure: batch, interactive, real-time, search, in-memory, and other processing tools.
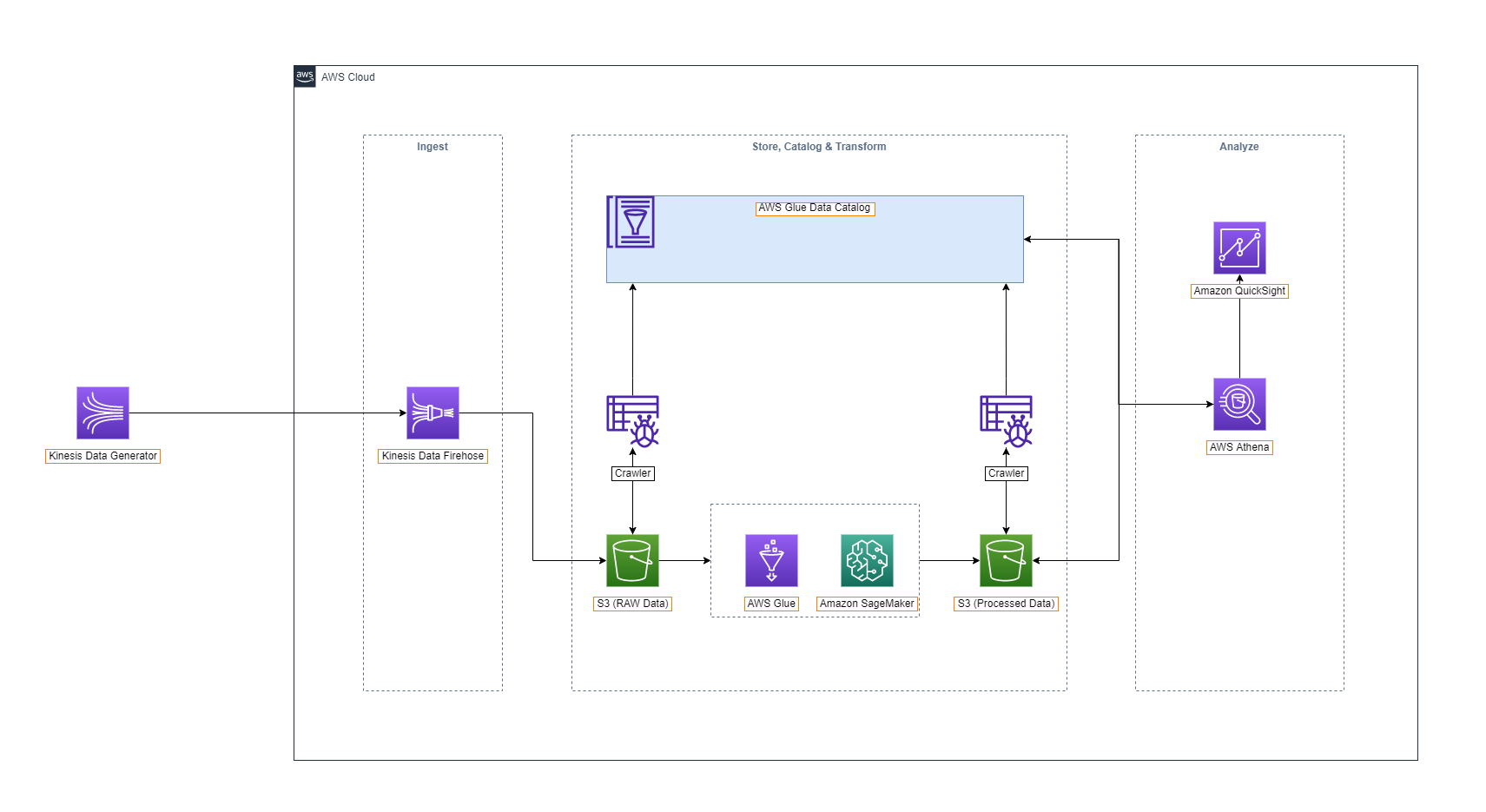
We will utilize AWS Glue as our data catalog. Amazon Athena will be used to query data within the data lake, and Amazon QuickSight for data representation.
You are a member of a Data Analysis team working for a music startup company. You will carry out the exploration, analysis, and statistics from the data.