Create Glue Crawler
Create Glue Crawler
-
Access the AWS Management Console.
- Find AWS Glue.
- Select AWS Glue.
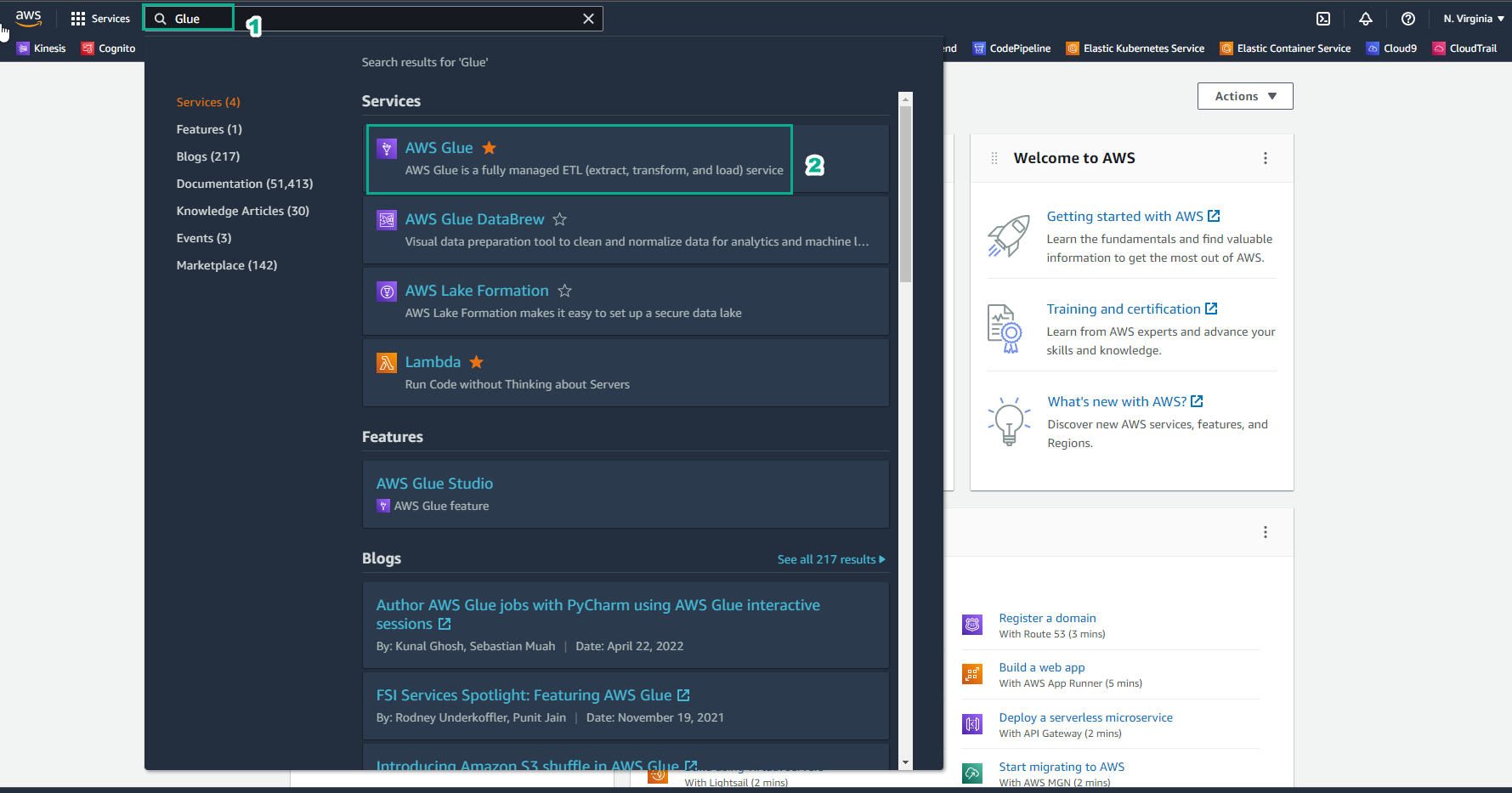
-
In the AWS Glue interface, select Crawlers.
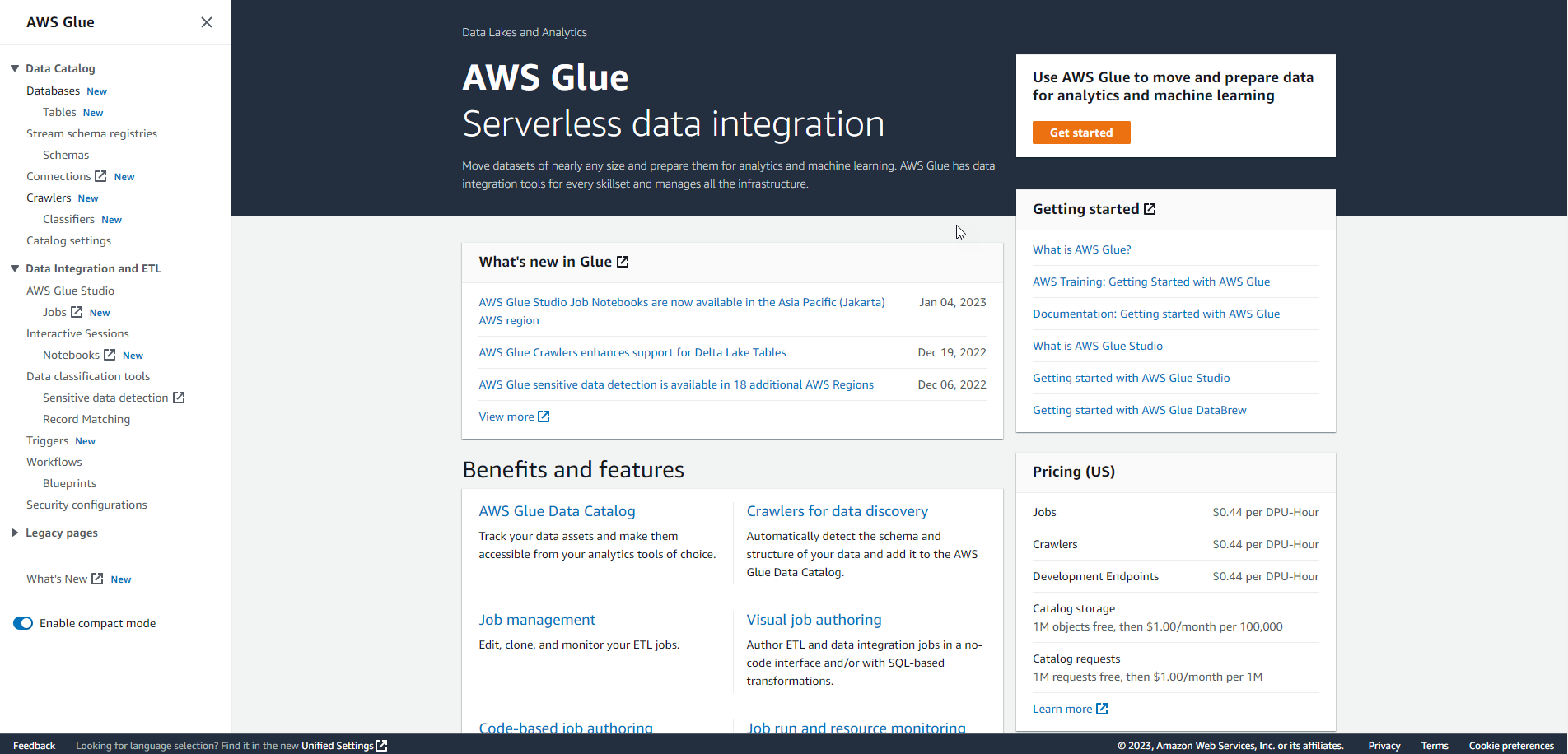 .
. -
Choose Create Crawler.
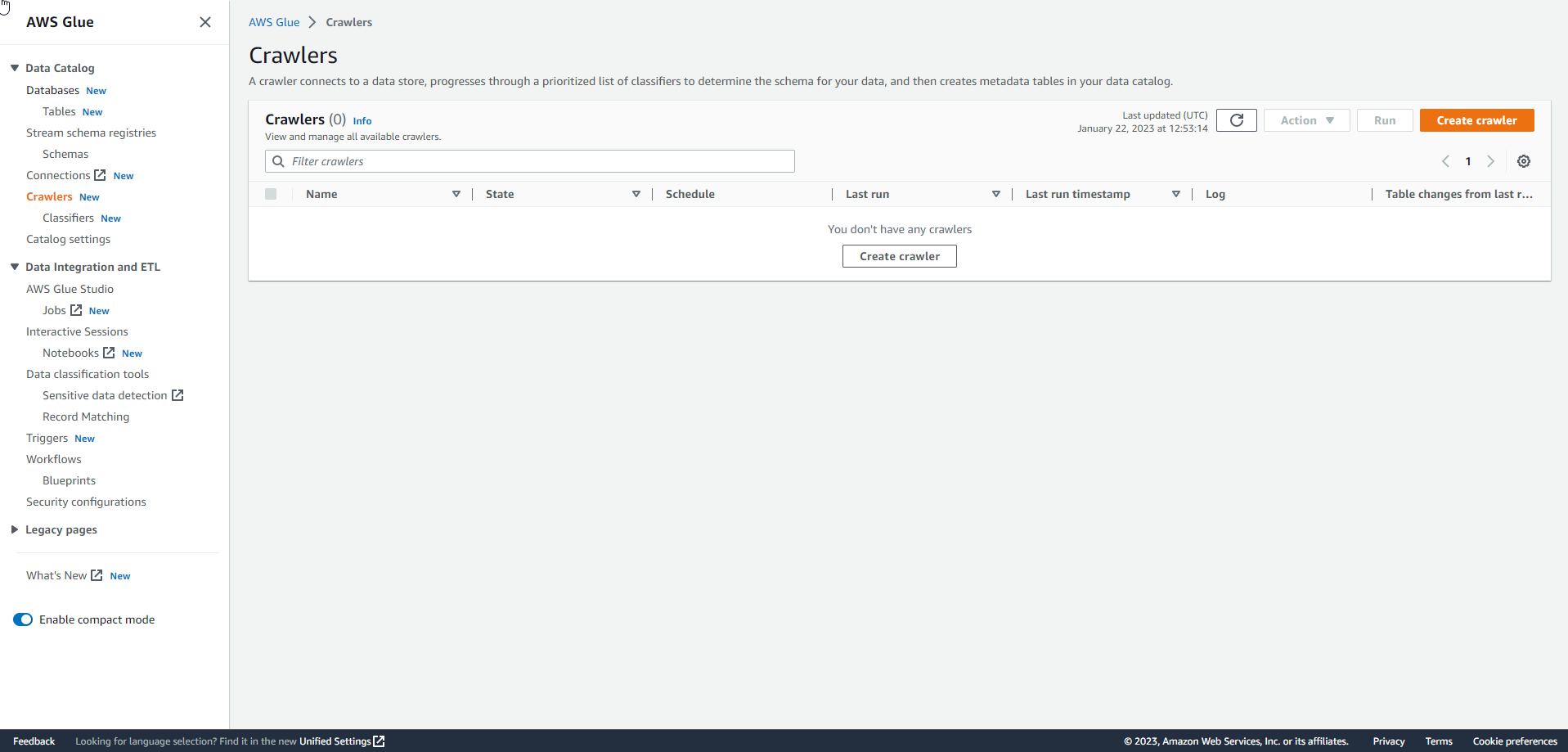 .
. -
In the Add Crawler interface, enter Crawler name as
summitcrawlerand select Next.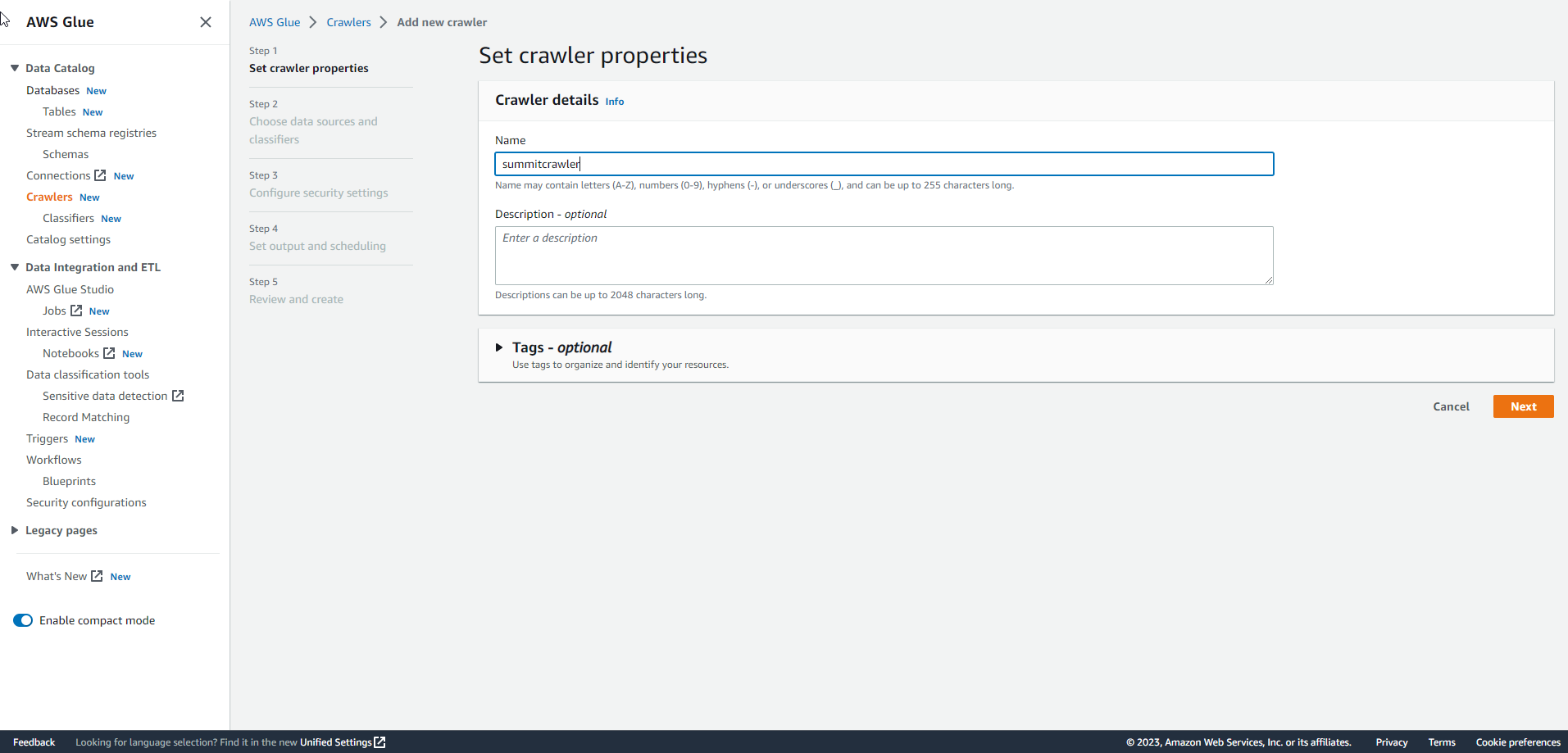 .
. -
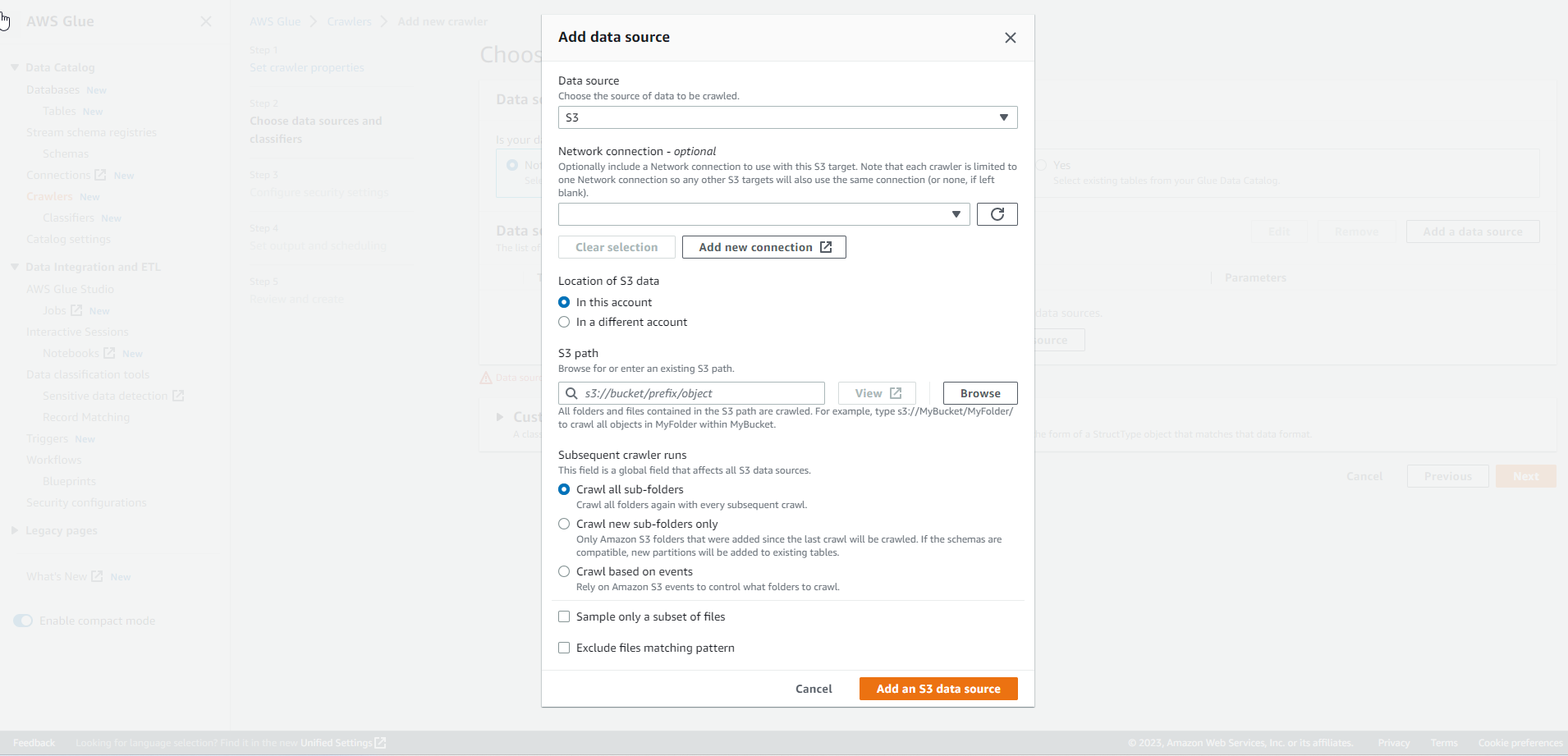
For Add data source, select S3.
 .
. -
Choose S3 path through Browse. You can choose the path as per your preference. Also, select Crawl new sub-folders only and Add an S3 data source.
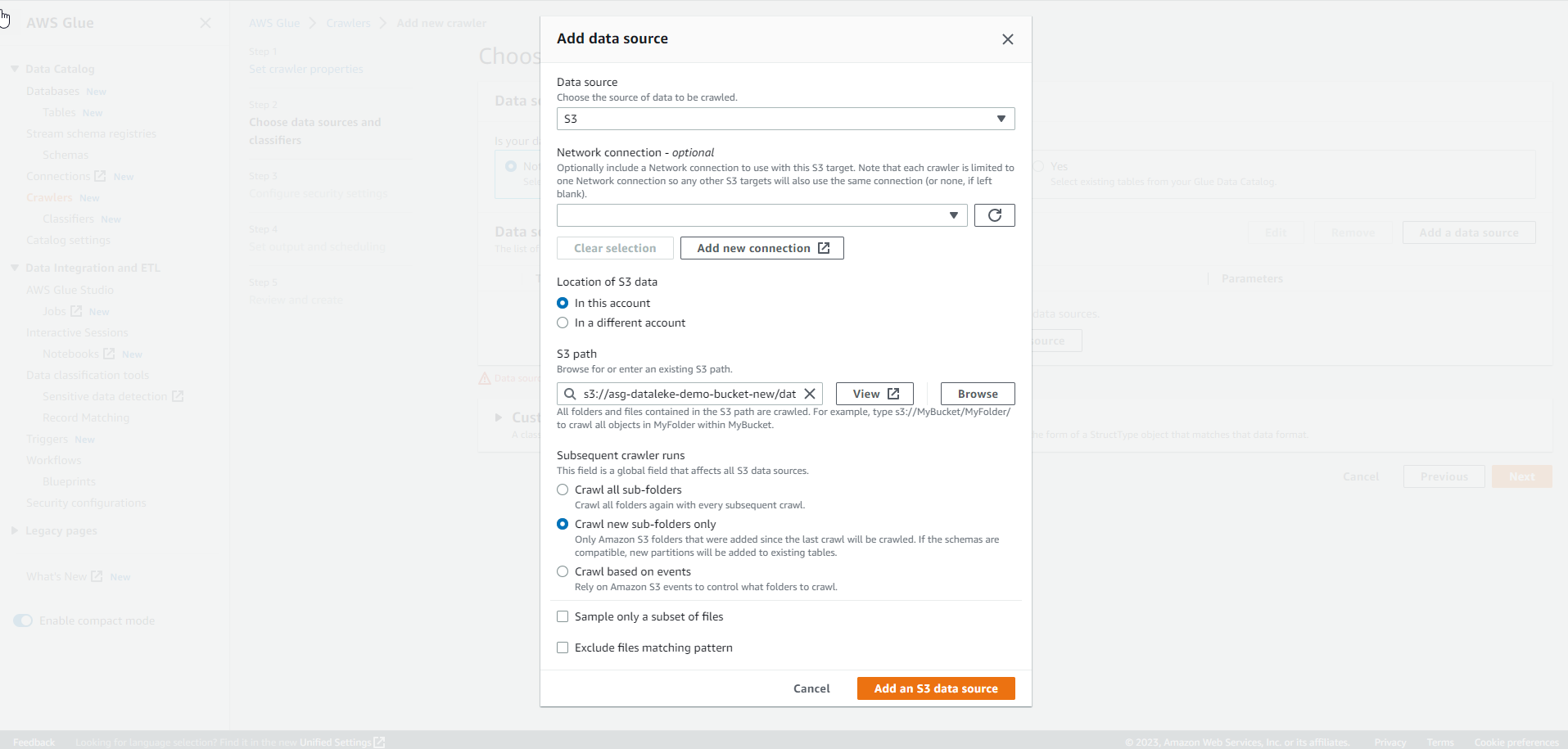 .
. -
After adding the data source, select Next.
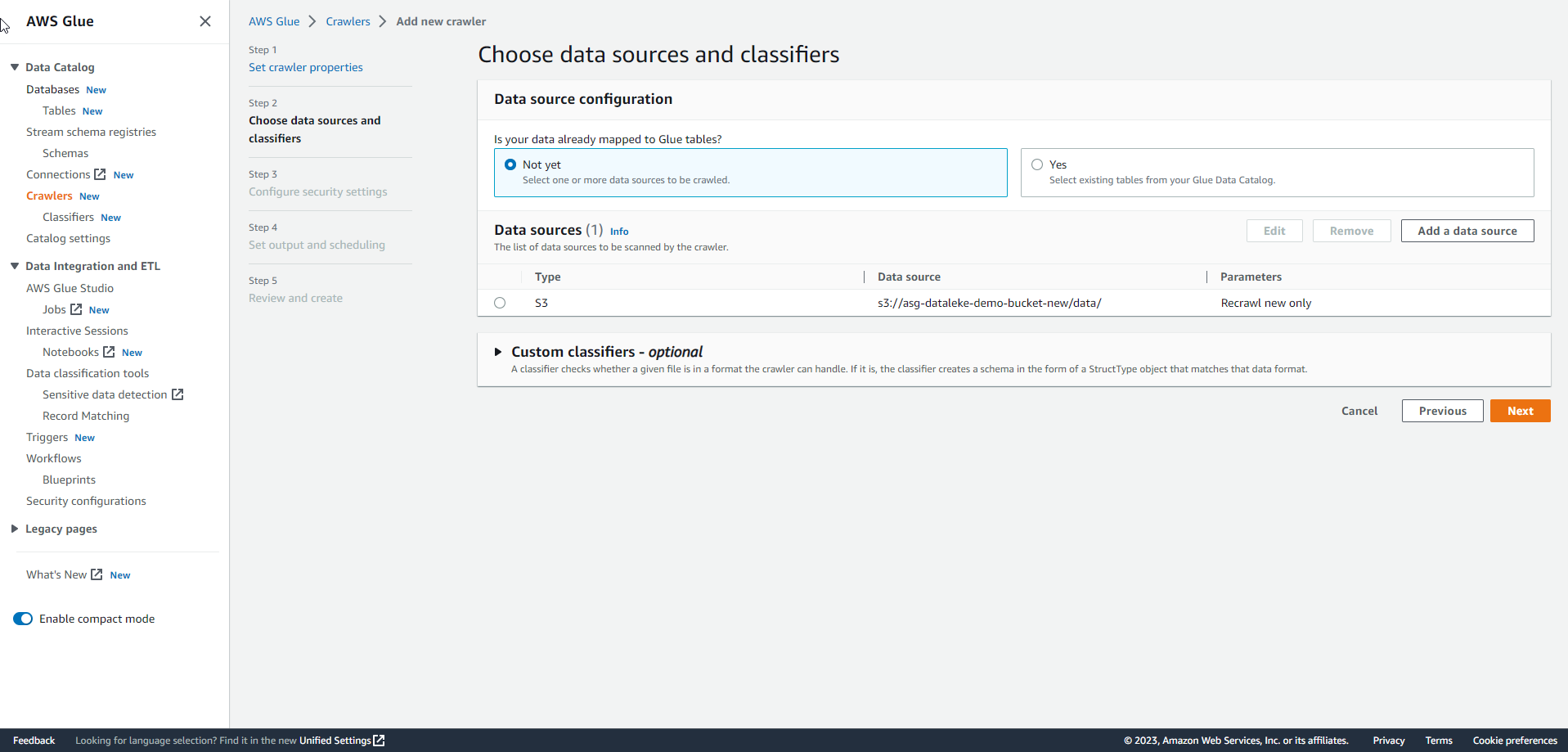 .
. -
For IAM role, you can either create a new role by selecting Create new IAM role or choose a pre-prepared role. Then, select Next.
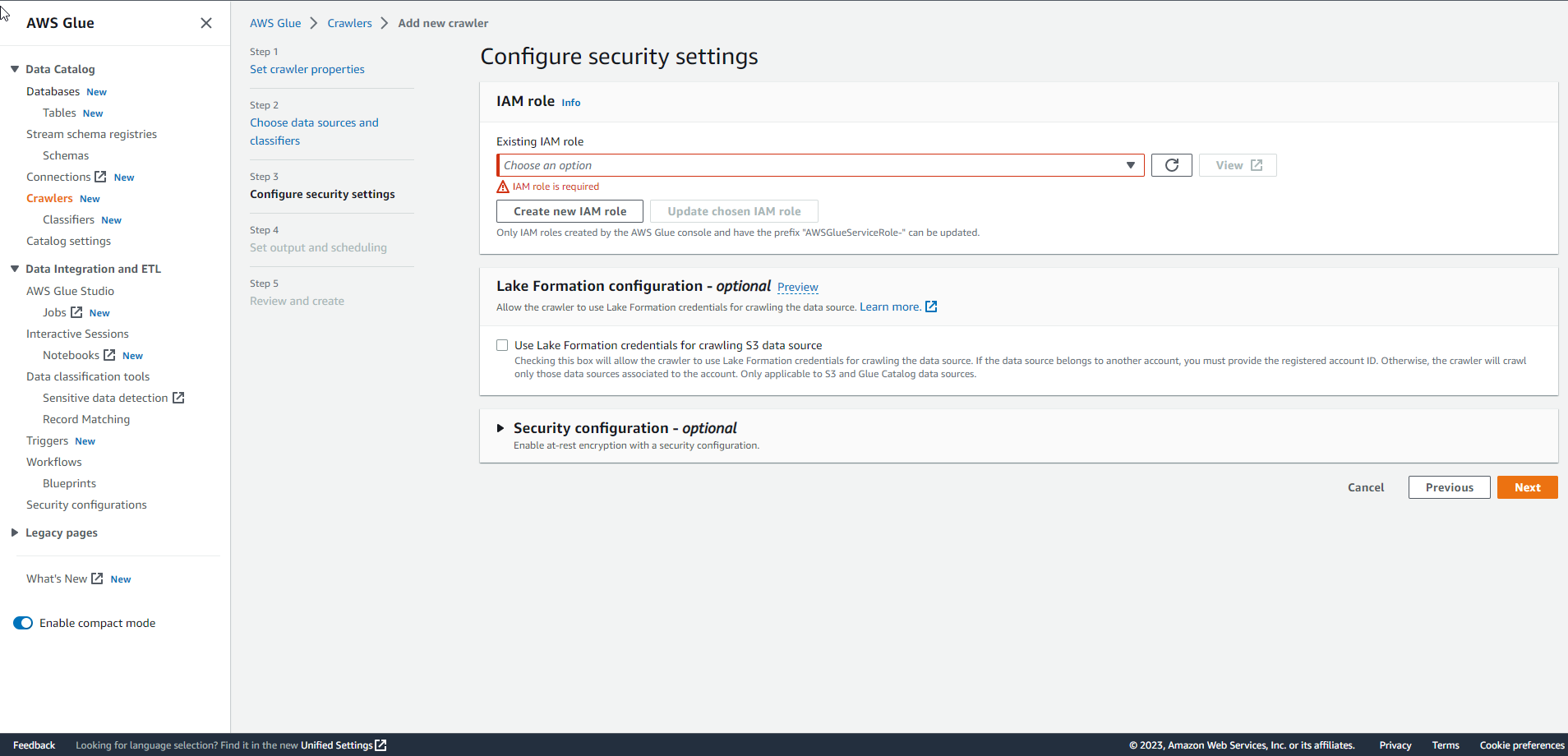 .
. -
For Target database, perform Add database.
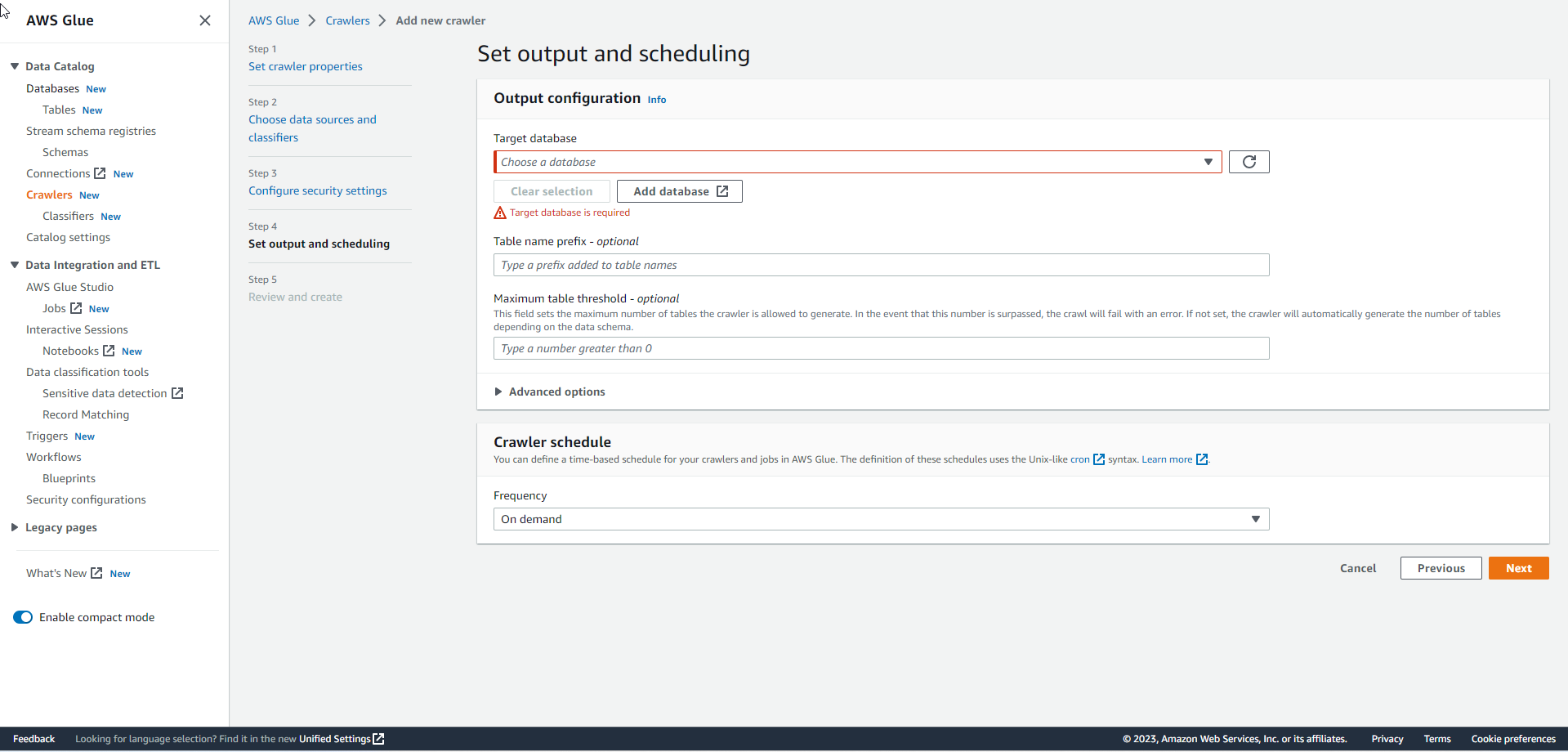 .
. -
Create a database by entering the database name as
summitdband selecting Create database.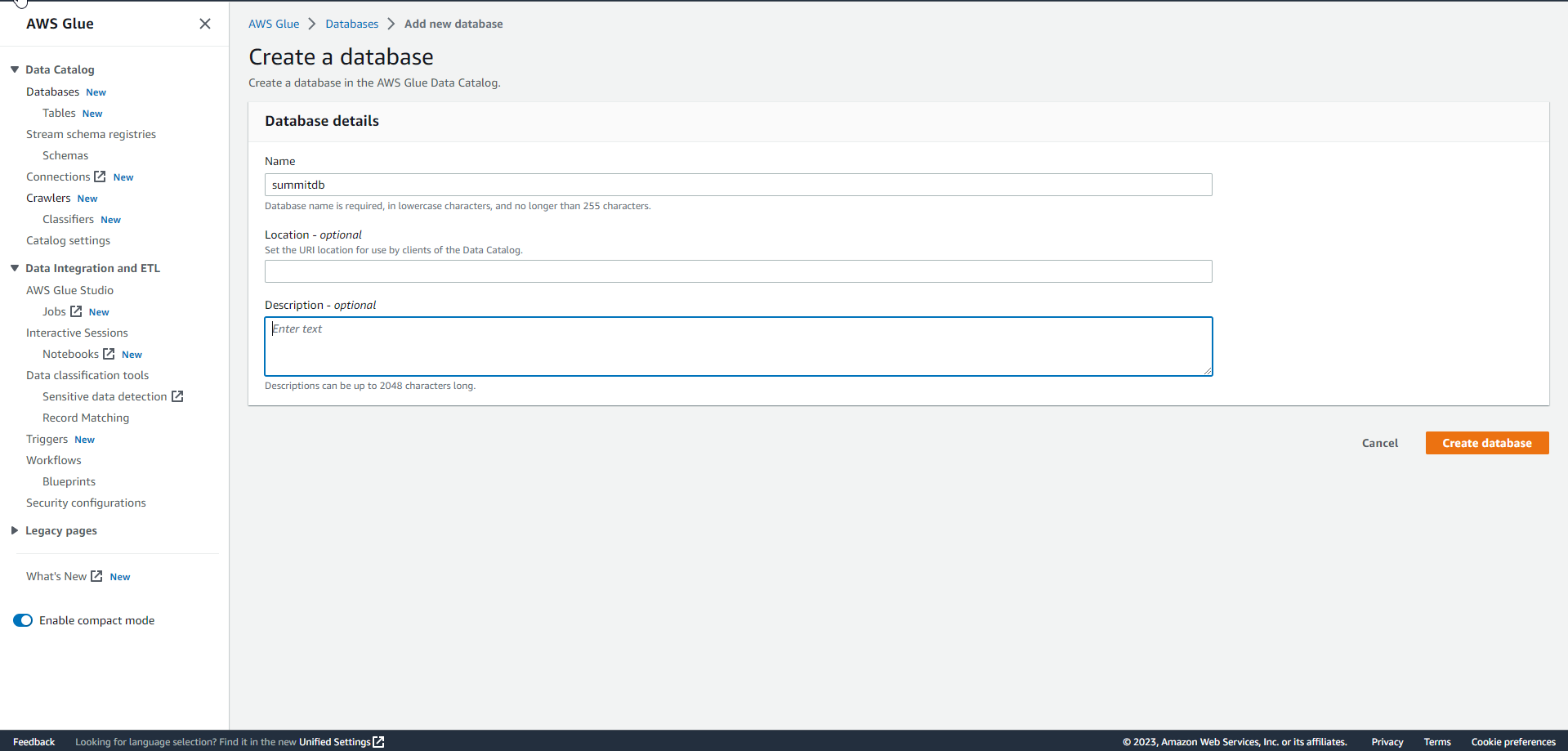 .
. -
After creating the database, select the database and choose Next.
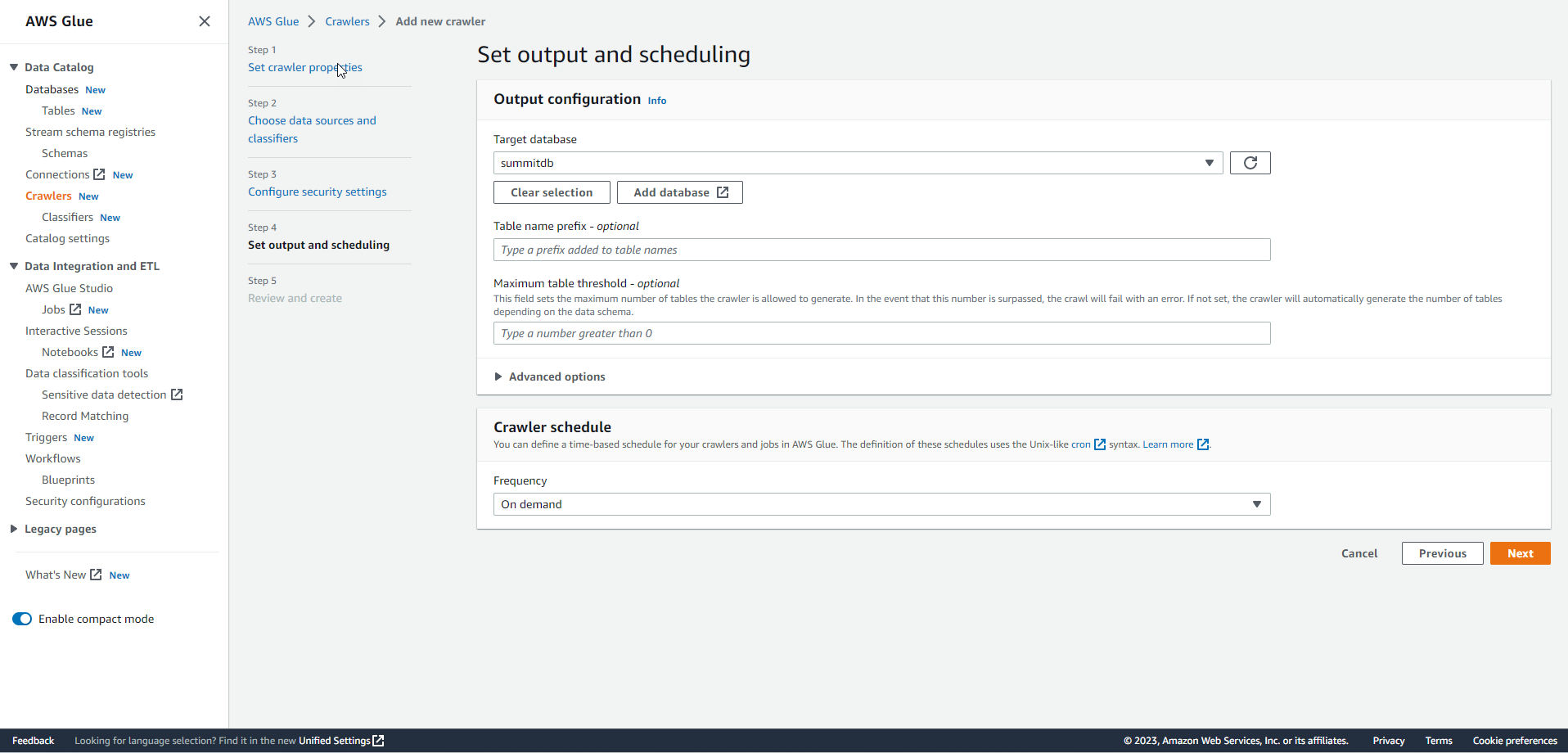 .
. -
Review the configuration and select Create crawler.
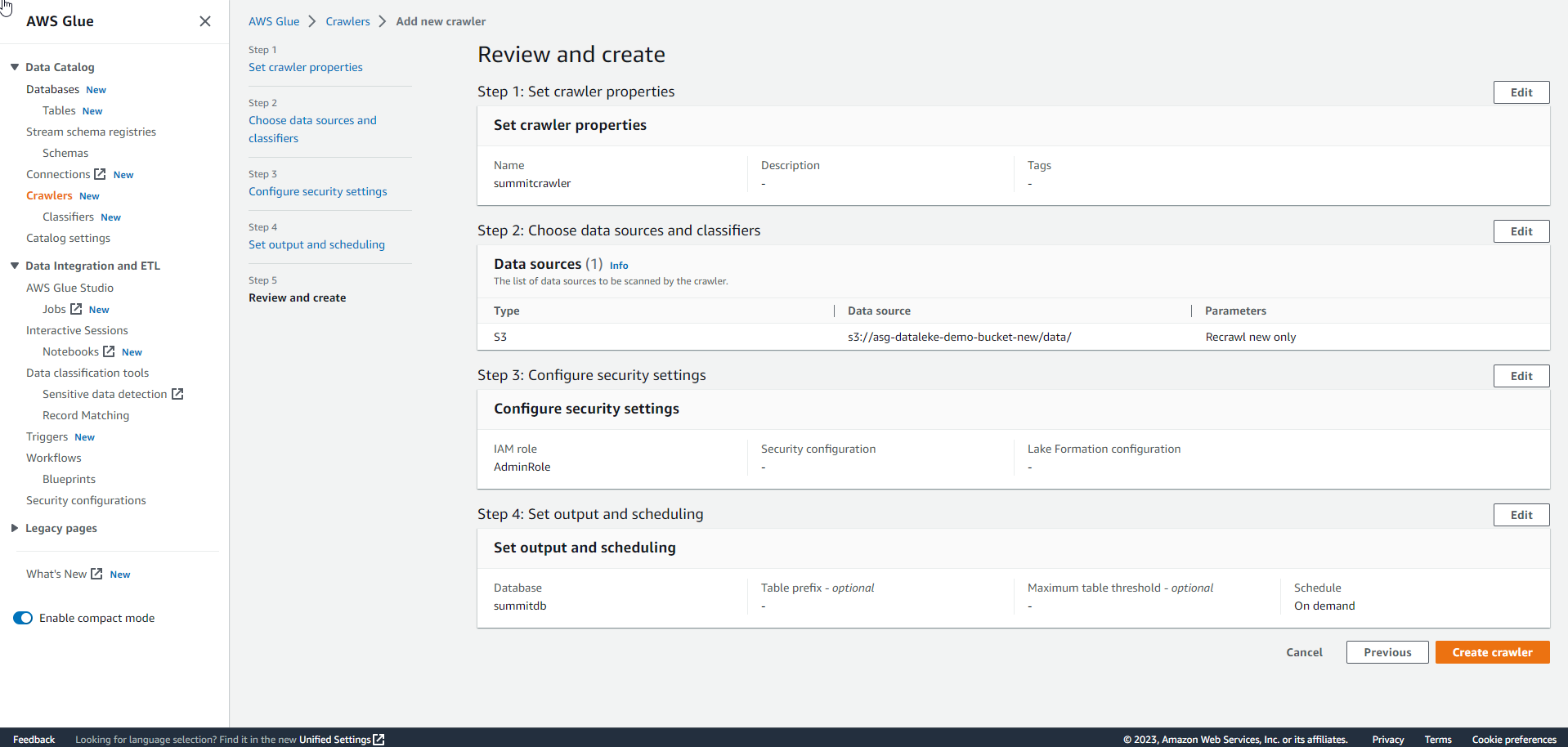 .
. -
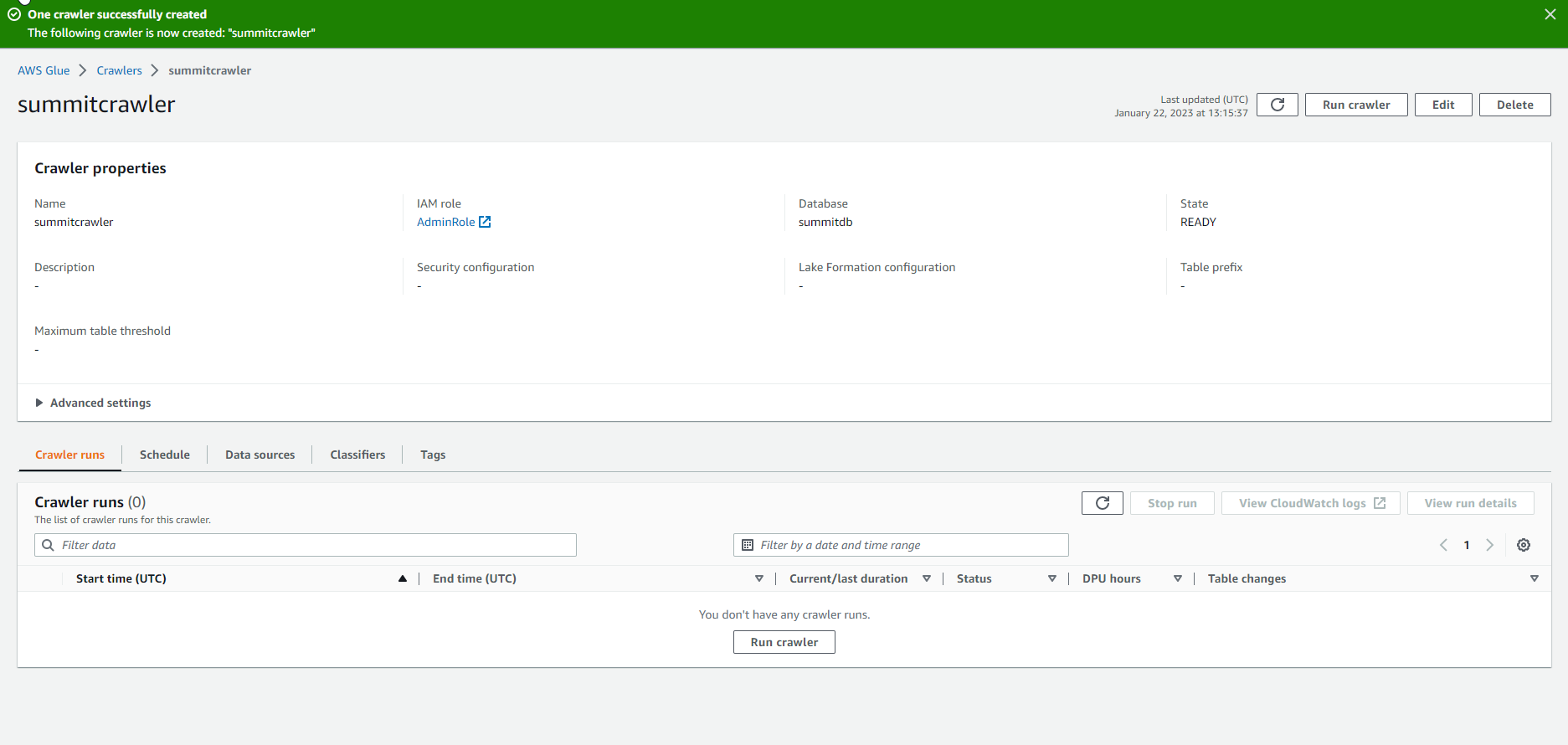
Crawler creation successful. Then, choose Run crawler.
 .
. -
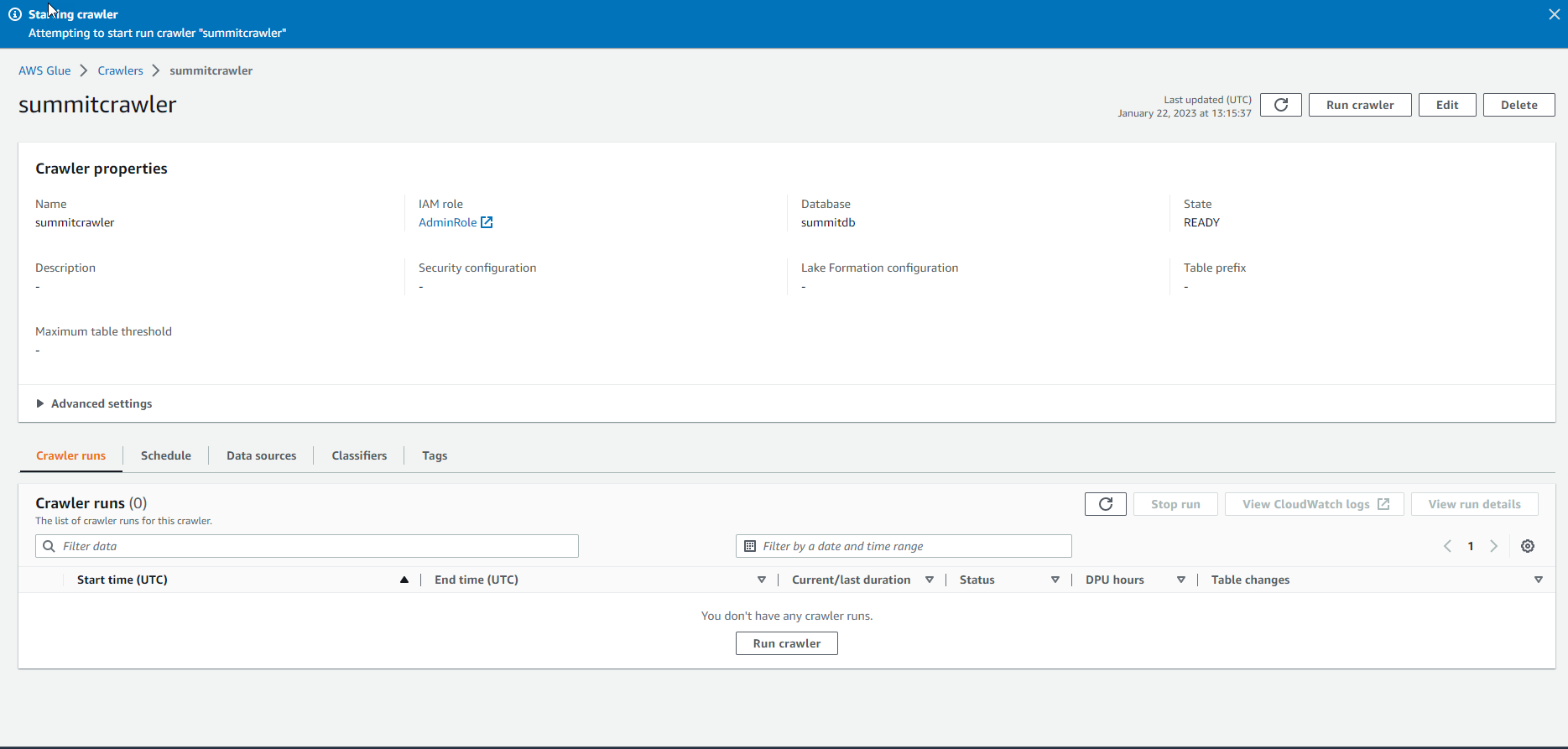
It takes about 1 minute to initialize the crawler.
 .
. -
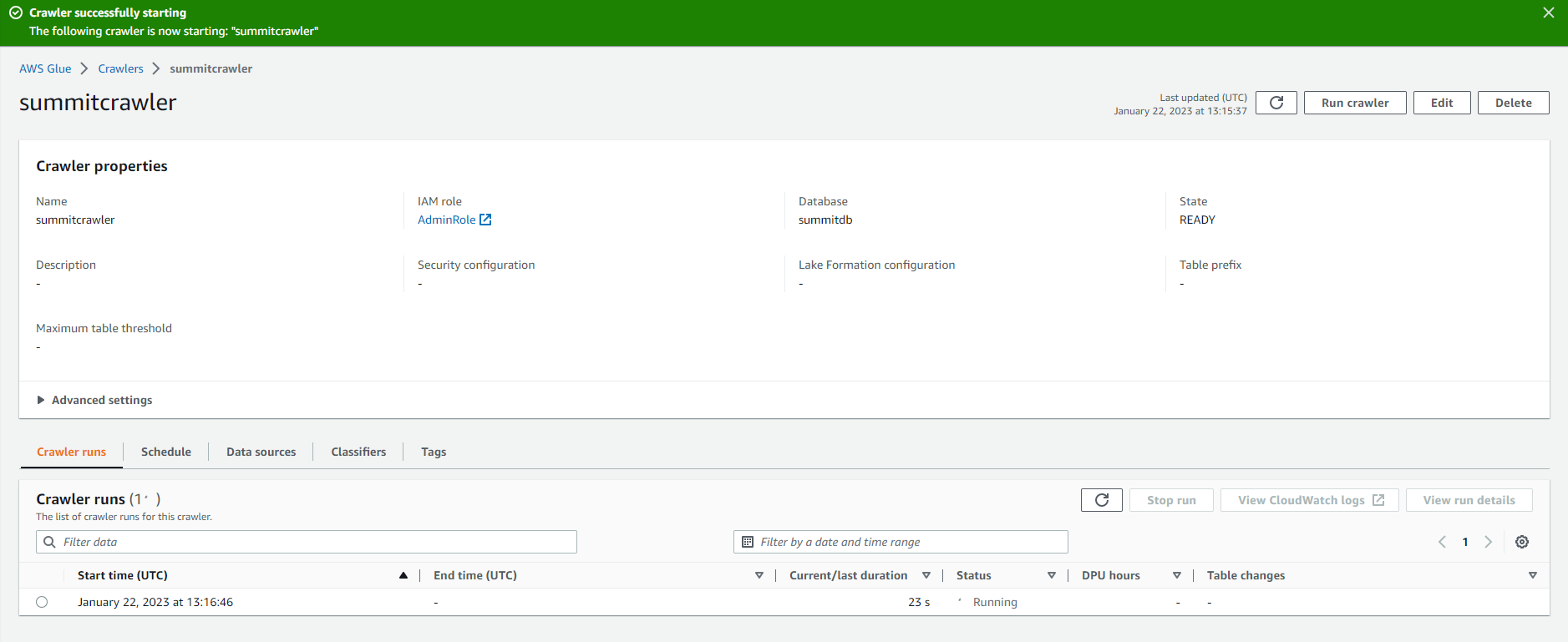
Crawler run initiated successfully.
 .
. -
After a while, the Crawler changes to the Stopping status.
 .
. -
When you see the crawler status as Ready.
 .
. -
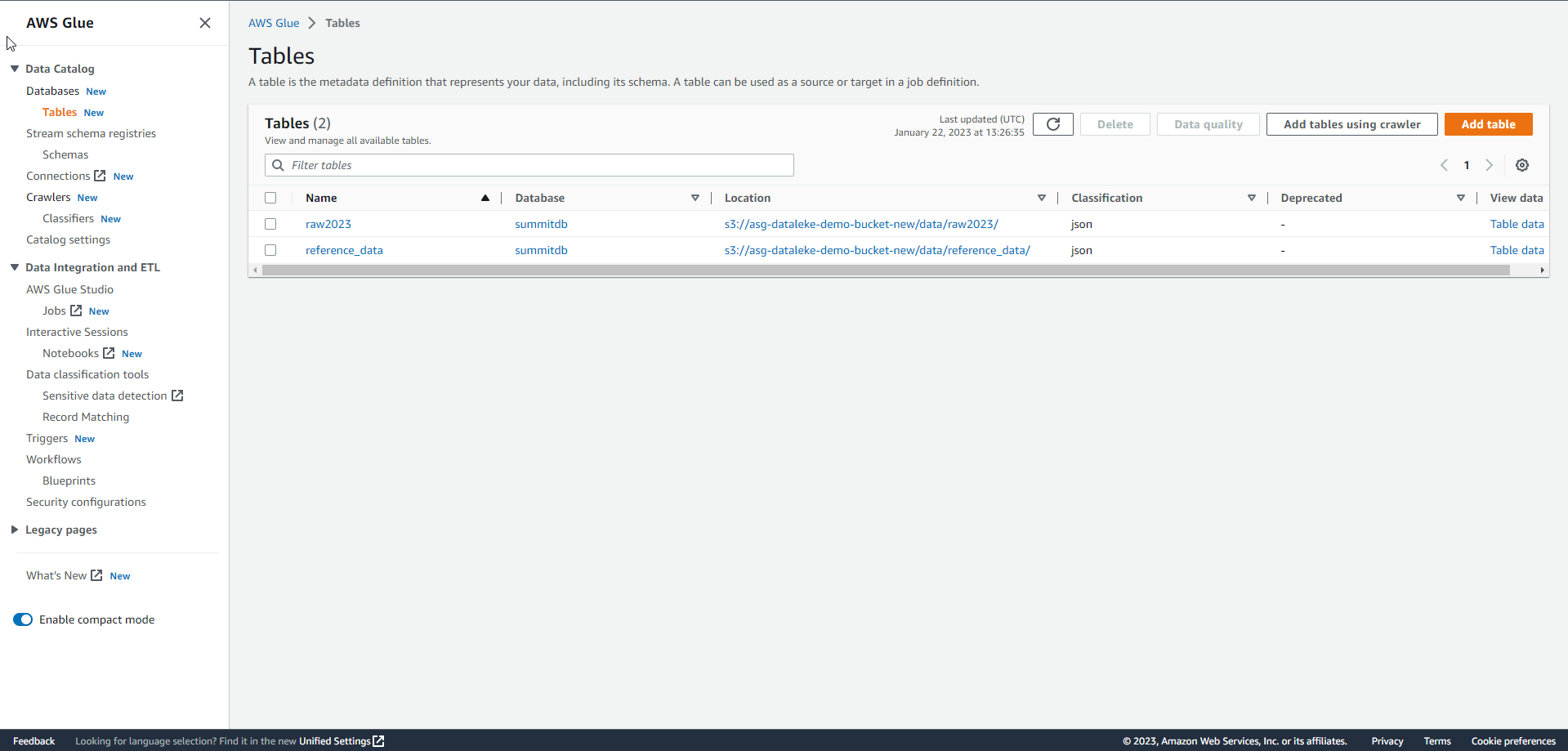
In the AWS Glue interface, select Table, and you will see 2 data tables.
 .
. -
Select the raw data table.
 .
. -
Explore the details of the data table.
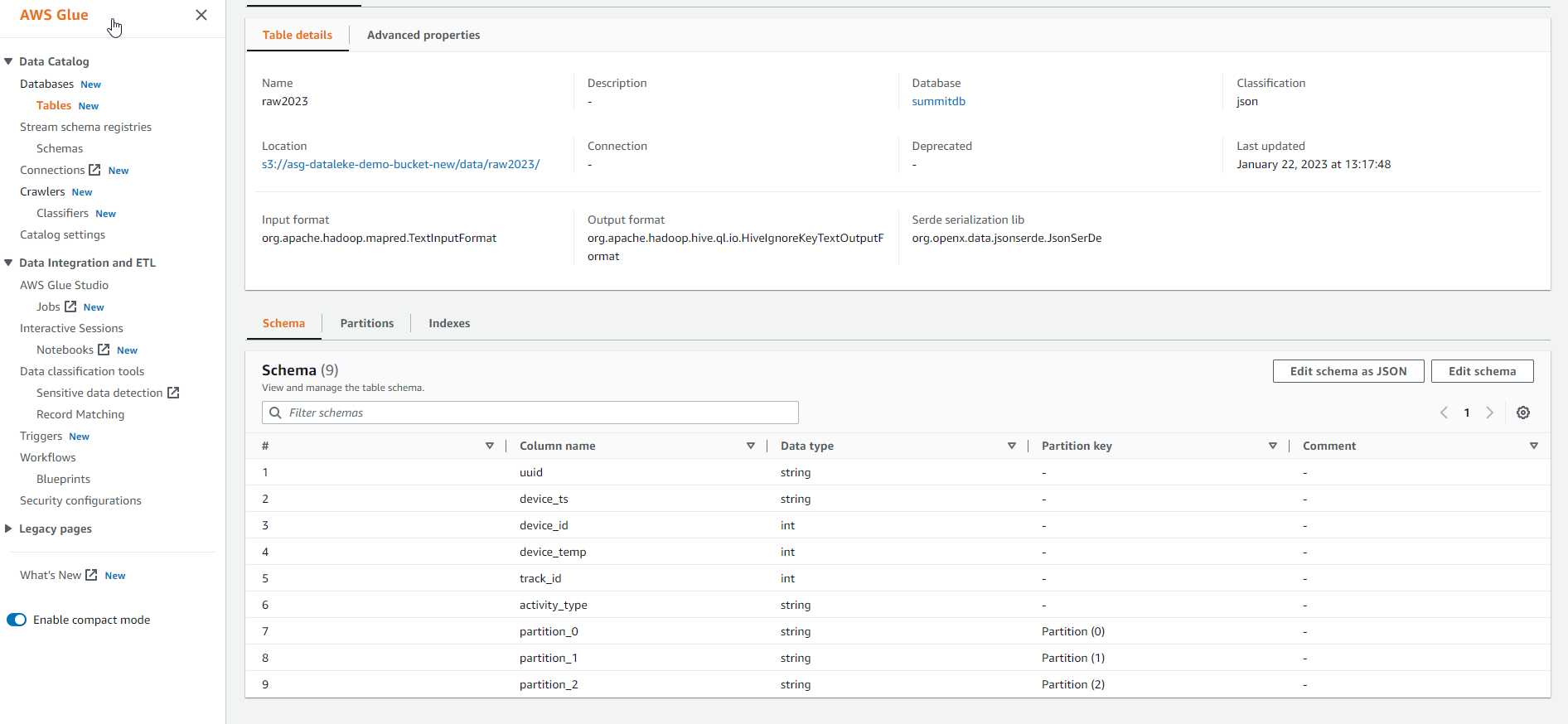 .
.