DataLake on AWS
Tổng quan
Data Lake là một thuật ngữ chuyên môn có liên quan đến Big Data (Dữ liệu lớn). Data Lake đơn giản là nơi chứa dữ liệu thô (chưa xử lý) chờ được xử lý phân tích và đưa ra các đánh giá nhận xét (insight).
Data Lake có các tính chất sau:
- Thu thập mọi thứ – chứa tất cả dữ liệu dạng thô hoặc đã được xử lý trong khoảng thời gian dài.
- Đa người dùng – cho phép nhiều người dùng tinh chỉnh, khám phá và làm phong phú dữ liệu.
- Truy cập linh hoạt – hỗ trợ nhiều cách thức truy cập dữ liệu (access pattern) trên cơ sở hạ tầng dùng chung: lô (batch), tương tác, trực tuyến, tìm kiếm, trong bộ nhớ và các công cụ xử lý khác.
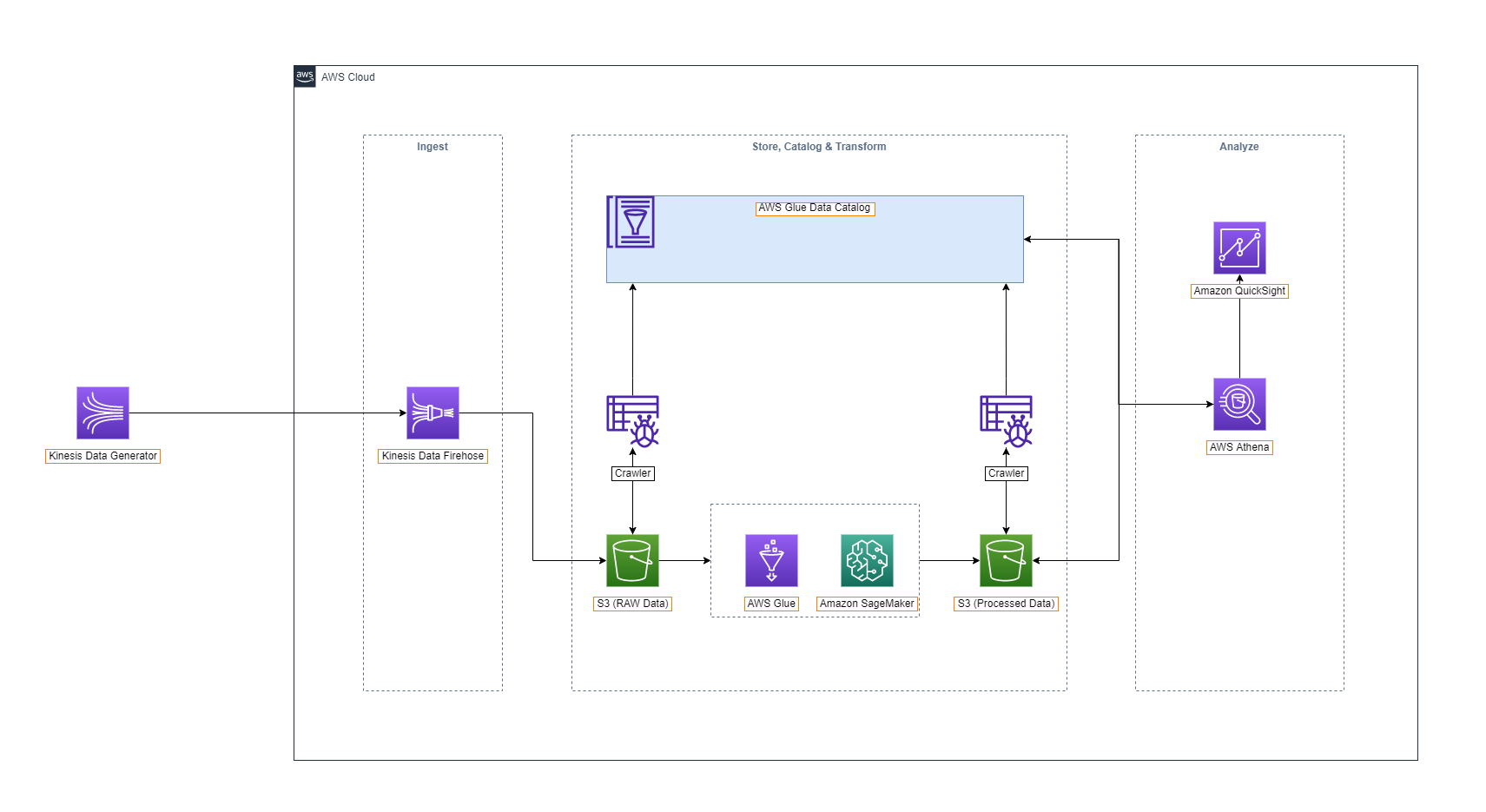
Chúng ta sẽ tận dụng AWS Glue để làm data catalogue. Amazon Athena được sử dụng để truy vấn data trong data lake và Amazon QuickSight để biểu diễn data.
Bạn là một thành viên trong đội Phân tích dữ liệu làm việc cho một công ty Start-up về âm nhạc. Bạn sẽ thực hiện khám phá, phân tích và thống kê từ dữ liệu